Recently, I set out to create my own photo organizer. In the process, I spent a lot of time experimenting with various image formats, which led me to an epiphany: JPEGs are ridiculously good at compressing image data, far beyond what you'd expect! Take this picture, for example:

This image is 299 by 400 pixels. Each pixel consists of three components, red, green, and blue. The brightness of each component is encoded as an 8-bit value, so each pixel contains three bytes of information. Multiply that by the number of pixels, and we get a file size of around 350 kilobytes. Yet the image shown above is actually only 43kB in size, just 12% of the value we just calculated. In other words, by encoding the image using the JPEG format, we can achieve a compression ratio of roughly 8:1. How does JPEG accomplish this astonishing feat? Let's dive in.
Chroma Subsampling §
The first trick that JPEG employs to remove unnecessary information is a technique called chroma subsampling. This step exploits the fact that our eyes are much more sensitive to changes in brightness than changes in color. After all, our eyes have about 100 million brightness-sensitive rod cells versus just 5 million color-sensitive cones. Thus, we can store the color info in the image at a lower resolution without losing too much quality.
In order to chroma subsample, we must first separate the color of a pixel from its brightness. JPEG accomplishes this by converting images to a color space called YCbCr. Like RGB, YCbCr pixels also consist of three values; however, the meaning of the values are different. Y is the luminance (brightness) of the pixel, and Cb and Cr together represent the color of the pixel without any luminance info.
But how is RGB mapped to YCbCr? In my opinion, the relationship between the two color spaces is best explained visually. Imagine a coordinate space where the x, y, and z axes represented R, G, and B, respectively. This would form a cube containing all possible RGB colors.
This cube has one important property: there exists a line through the cube where the R, G, and B values are all equal. One can imagine a coordinate system where we align the cube such that the luminance component (Y) extends along this line. We can then extract a slice of the cube for any given luminance, and assign the remaining two degrees of freedom to Cb and Cr.
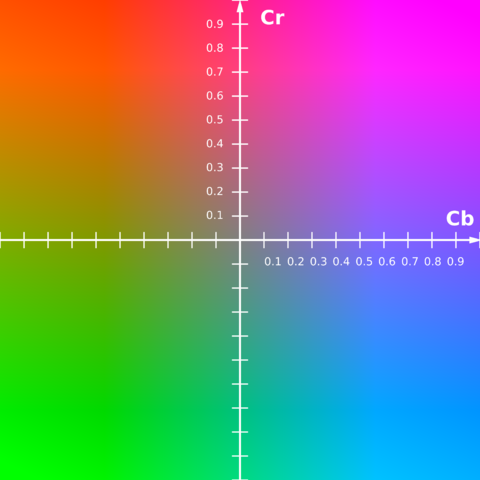
This is essentially how YCbCr works, except the RGB cube is slightly deformed in order to fit all the values into a range of [0, 1]. Here's a demo that shows the Cb-Cr planes as we adjust Y.
If you want a better view of what the Cb-Cr plane looks like, here is a slice of the YCbCr gamut at Y = 0.5.
When an image is stored as JPEG, the first thing that happens is that the RGB colors are converted to YCbCr. The Cb and Cr channels are stored at half the resolution of the full image, a scheme which is referred to as 4:2:0.
Let's compare what the components of the image look like in the two color spaces. Here's what the image looks like in RGB.

And here's what the image looks like in YCbCr:

As you can see, the importance of the luminance channel really shines through here. There is very little appreciable detail in the Cb and Cr channels, unlike in RGB space, where each channel is perceived roughly equally in the final image. We can safely discard much of the detail in the chrominance channels without sacrificing too much quality in the final image. However, this still doesn't bring us to the astounding compression ratios that JPEG achieves on a regular basis. For that, we'll need to go deeper into the compression process.
Discrete Cosine Transform §
In the previous step, we reduced size by getting rid of color information. However, we can also drastically reduce size by getting rid of unnecessary spatial information. What does that mean? Consider this photo of a flower.

If we zoom in close on the two highlighted regions, it becomes clear that not all image data is created equal. The region on the left contains much more detail than the one on the right, yet they are currently represented in the same number of bytes.

Like last time, the problem now becomes representing the image data in a way that lets us separate the important parts from the unimportant parts. JPEG accomplishes this by converting the image to the frequency domain.
Right now, the image exists in the spatial domain. We can think of it as a function that takes a pixel position and outputs an intensity value. However, thanks to the work of the French mathematician Joseph Fourier, we know that signals of this type can also be expressed as the sum of an infinite series of sinusoids with varying frequencies. From his insight came the concept of the Fourier transform, which converts our function from the spatial domain to the frequency domain (where it would map the frequency of each component to its amplitude). This allows us to discard the high-frequency components, which aren't as important in reconstructing the signal.
JPEG does not use the Fourier transform; instead, it uses the closely related discrete cosine transform, whose characteristics make it better suited for use in lossy compression. Before we go further, try drawing a waveform using your mouse in the box on the left. The DCT of the signal will be taken and the signal will be reconstructed and displayed on the right.
You can use the slider to change how many DCT coefficients are used to reconstruct the signal.
Notice how removing high-frequency components from the signal affects the quality much less than the lower-frequency components. JPEG essentially does the same thing, but in 2D. The image is broken up into 8x8 blocks, which are then decomposed into a matrix of 64 coefficients.

Note that DCT itself doesn't actually save us any bytes. We started with 64 pixels, and ended with 64 DCT coefficients.
Quantization §
Instead of simply removing all high frequency components after a certain cutoff like we did in our 1D DCT example, JPEG uses a strategy called quantization. Essentially, each DCT coefficient is divided by the corresponding value in an 8x8 quantization table, and then rounded down. The result is that many components of the quantized DCT coefficients will become zero, making the data more conducive for lossless compression.
Let's see how quantization works for ourselves. Say we've just performed DCT on some image data:

We now have a table of DCT coefficients.
DCT Coefficients
| -138 | 68 | 192 | 2 | 69 | -24 | -7 | -29 |
| -4 | 73 | 1 | -74 | 5 | -6 | 18 | 0 |
| 166 | 13 | -40 | -60 | -73 | 20 | -16 | 42 |
| 10 | 3 | -38 | -23 | 48 | 29 | -22 | -7 |
| 9 | 5 | -10 | 31 | -61 | 49 | 26 | -10 |
| -5 | -7 | 19 | 24 | -17 | 9 | -4 | 2 |
| 49 | -6 | -68 | 31 | 30 | -9 | 13 | -16 |
| 9 | -6 | -11 | 15 | -3 | -7 | -2 | -3 |
Next, it's time to quantize. We will be using the Independent JPEG Group's recommended quantization table for this example.
IJG Quantization Table
| 16 | 11 | 10 | 16 | 24 | 40 | 51 | 61 |
| 12 | 12 | 14 | 19 | 26 | 58 | 60 | 55 |
| 14 | 13 | 16 | 24 | 40 | 57 | 69 | 56 |
| 14 | 17 | 22 | 29 | 51 | 87 | 80 | 62 |
| 18 | 22 | 37 | 56 | 68 | 109 | 103 | 77 |
| 24 | 35 | 55 | 64 | 81 | 104 | 113 | 92 |
| 49 | 64 | 78 | 87 | 103 | 121 | 120 | 101 |
| 72 | 92 | 95 | 98 | 112 | 100 | 103 | 99 |
Dividing our matrix of coefficients and rounding down the results yields the following quantized values:
Quantized DCT Coefficients
| -8 | 6 | 19 | 0 | 2 | 0 | 0 | 0 |
| 0 | 6 | 0 | -3 | 0 | 0 | 0 | 0 |
| 11 | 1 | -2 | -2 | -1 | 0 | 0 | 0 |
| 0 | 0 | -1 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
As you can see, many of the high-frequency components have become zero. This is what is accomplished by quantization; it hasn't actually reduced the size of our data yet (we still have 64 numbers), but by getting rid of unnecessary precision it has made the DCT coefficients more easily compressed by a lossless compression algorithm that will be applied next.
Lossless Compression §

In the final step of JPEG compression, the DCT matrix is unraveled according to a zigzag pattern, and Huffman coding is applied to compress the data. How Huffman coding works is beyond the scope of this article, but if you want a concise, accessible explanation of the technique, I encourage you to check out Tom Scott's video on the subject.
Conclusion §
If you've reached this point, congratulations; you now have a high-level understanding of the processes that take place every time you save an image as a JPEG.
There's a lot that isn't covered here. If you want to know more about the mathematics of the Fourier transform, or explore the actual implementation details of the JPEG standard, I've included some links that you can follow to continue learning about the fascinating enigma that is the JPEG format.
Further Reading §
- ITU - T.871: JPEG File Interchange Format (JFIF)
- CCITT - T.81: Digital Compression and Coding of Continuous-Tone Still Images - Requirements and Guidelines
- Better Explained - An Interactive Guide to the Fourier Transform
- Parametric Press - Unraveling the JPEG
- Christopher T. Jennings - How JPEG Works